In my last blog post, I discussed how agent skills can uplift an LLM’s capabilities by giving it access to live data and tools. That pattern is powerful for bridging the gap between static training knowledge and dynamic real-world information.
Large language models and especially reasoning models are able to make plans on their own, so how efficient is the use of a specific skill? In this blog we’ll dive into benchmarking the usefulness of skills and validate the skill for implementing NuGet packages in a .NET project.
Reasoning a plan
Modern reasoning models do not just predict the next token. They decompose a task into discrete steps, evaluate
dependencies between those steps, and execute them in order. Ask a model like Claude Sonnet to “add MediatR to my
.NET project” and it will produce a plan on its own: identify the right package, determine the target project,
run dotnet add package, register the services in the DI container, and verify the build still passes.
That plan is not hardcoded. The model constructs it at inference time based on its understanding of the task. Give it a different prompt and it builds a different plan. This is what makes reasoning models so effective for software engineering tasks: they adapt to context rather than following a fixed script.
Each new generation of models gets better at this. Plans become more complete, edge cases get handled earlier, and the model recovers more gracefully when a step fails. The gap between what a reasoning model can figure out on its own and what it needs to be told is shrinking with every release.
That raises an obvious question.
Reasoning vs Skills
If reasoning models can already figure out what to do, why bother writing skills at all?
The answer depends on which model you are running and what you are asking it to do. Frontier reasoning models like Claude Sonnet or Opus can decompose most tasks into a sensible plan without any external help. But not every team runs the latest frontier model. Older and cheaper models lack that same planning capability, and even the best models fall short when the task depends on information that did not exist at training time.
This is where skills earn their place. A skill does not compete with the model’s reasoning, it extends it. For straightforward code generation or refactoring, a reasoning model can handle the steps on its own. But for tasks that require live data, enforce a specific workflow, or coordinate external tools, the model needs guidance it cannot invent from static weights alone.
There is a natural lifecycle to consider. As models improve, some skills will become redundant. A skill that once walked a weaker model through a multi-step process might add nothing but latency to a stronger one. However, skills that grant the model access to external tools or encode a team-specific workflow remain valuable regardless of model capability. No amount of reasoning can substitute for querying a live API or following a compliance checklist the model has never seen.
The practical takeaway: do not assume a skill is always helpful, and do not assume reasoning alone is always enough. The only way to know is to measure.
Benchmarking skills
Measuring a skill’s value requires a controlled comparison: run the same prompt in the same repo context on the same model, with and without the skill loaded, then compare the outputs side by side. That is exactly what the agent-creator skill in Claude Code now supports. It automates the benchmark by executing a single prompt in two parallel sessions, one with the target skill active, one without and surfaces the differences so you can judge whether the skill actually improved the result.
The approach is straightforward. You give the agent a representative task, and it handles the rest: generating the benchmark prompt, running both sessions, and presenting the outputs together. No manual setup, no toggling configurations between runs. The model does the heavy lifting and gives you a clear before-and-after comparison.
This workflow is not exclusive to Claude Code. The same agent-creator skill can drive benchmarks in other tools like GitHub Copilot, but it requires you to configure the skill yourself. Claude Code handles that wiring automatically, which makes it the fastest path to a first benchmark.
Validating the NuGet package skill
Time to put the nuget-package-implementation skill to the test. The benchmark runs on Claude Sonnet 4.6, a current frontier
model, so any improvement the skill delivers cannot be dismissed as compensating for a weak model.
The prompt is straightforward:
“benchmark the nuget-package-implementation skill with and without the skill loaded. I want a side-by-side comparison so I can see the difference.”
The agent takes it from there. It generates a benchmark prompt, spins up two parallel sessions, one with the skill active, one without, and presents the outputs together. The creator skill describes the steps the model should take to validate. It even chooses the benchmark prompt:
“How do I add MediatR to Catalog.Application?”
The following side-by-side output is shown after running the benchmark:
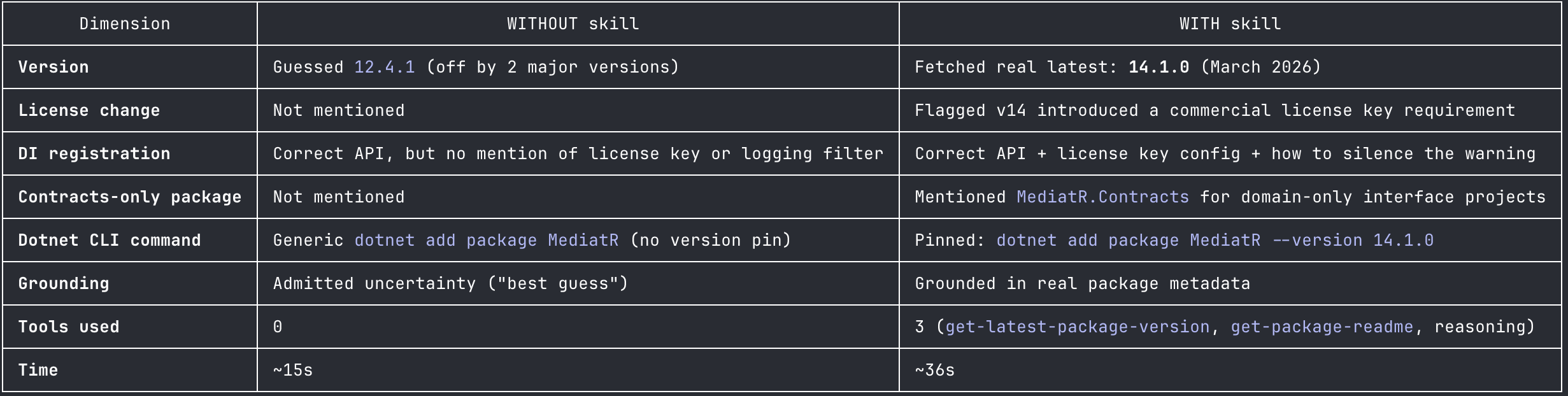
For this task, the benchmark shows a clear quality lift at the cost of additional latency. In the case of a package implementation, speed is not a relevant metric, it is more important to get the right version, catch breaking changes, and be aware of any license shifts.
The model surfaced the following key differences:
- Version accuracy: Without the skill, the suggested version was wrong by two major versions (12.x vs 14.x). In a real project that could mean silently pulling in breaking changes or missing critical fixes.
- Breaking change detection: The skill caught a significant v14 behavior change, a commercial license key requirement, that base knowledge had no way of knowing. No amount of reasoning can surface a licensing shift that happened after training.
- Cost: The skill takes roughly 2x longer due to tool calls, but delivers verifiably correct, up-to-date information rather than confident-sounding guesses.
- The core value: The skill turns “what I recall” into “what the package actually says today”. Critical for fast-moving packages or anything past the knowledge cutoff.
The takeaway is clear: even on a frontier model, the skill delivers measurably better results. It catches version drift, surfaces
breaking changes, and warns about license shifts that are not top of mind when you run dotnet add package. The added latency
is real, but it is a small price for answers you can actually trust.
Skills are not write-once artifacts. They live alongside the models they extend, and their value shifts as those models improve. Upgrading to a new model might make some skills redundant, but it does not automatically retire them. The only way to know whether a skill still earns its keep is to measure it: run the same prompt with and without the skill, compare the outputs, and let the results speak. Regular benchmarking is the only way to catch skill drift before it becomes dead weight.
Wrapping up
Skills are not write-once artifacts. They live alongside the models they extend, and their value shifts as those models improve. The only way to know whether a skill still earns its keep is to measure it: run the same prompt with and without the skill, compare the outputs, and let the results speak.
The nuget-package-implementation skill proved its worth even on Claude Sonnet 4.6, a current frontier model. It caught version
drift, surfaced a breaking license change, and delivered verifiably correct information where the base model could only offer
confident guesses. That is not compensating for a weak model, it is extending a strong one with live data it cannot invent from
static weights.
As models continue to evolve, some skills will become redundant. A skill that once guided a weaker model through a multi-step workflow might add nothing but latency to a stronger one. Regular benchmarking catches that drift before it becomes dead weight. Treat your skills like any other dependency: validate them, prune what no longer delivers value, and keep investing in the ones that do. Run them on an explicit lifecycle: adopt, monitor, retire.